I was very young when I first saw 2001: A Space Odyssey. I think that was the moment when my awe with AI began. For me, HAL 9000 epitomized the “perfect” AI assistant. An intelligent machine, which is always next to you, adaptable with how you speak and is super capable of managing complex operations, and of course seemingly infallible.
I was so hooked with the plot and at that age, I was looking forward to seeing how machines like HAL will operate autonomously. I was convinced with whatever understanding I could gather during my childhood, that since machines follow logic so they can never go wrong.
But as the story unfolded, HAL’s perfection became terrifying. Its reasoning without humans in the loop, led to catastrophic consequences.
“I’m sorry, Dave, I’m afraid I can’t do that” – still haunts me!
A system that could process and calculate beyond human ability was still vulnerable to unintended outcomes, and worse, there was no simple way for humans to intervene once HAL set its course. That early lesson stuck with me, intelligence alone is not enough. Without collaboration and correction, even the most capable AI can go rogue.
If we look today, this principle is shaping the way we design modern AI systems. We’ve gone from fully manual segmentation, where an artist painstakingly outlines every detail or radiologists tracing every tumor contour, to pre-trained models that arrive with a strong prior sense of shape and texture. Then came systems that propose segmentations, waiting for human correction: a kind of call-and-response where the model makes a first draft and the human decides if it fits the bigger picture.
We all are quite familiar with foundational models like ChatGPT or DALL-E, which can perform a wide range of tasks, right from text generation to creating realistic images from prompts, with additional capabilities like adapting to diverse applications with minimal fine-tuning, all without requiring task-specific training from scratch. These systems have changed our expectations, instead of narrow tools, we now think in terms of adaptable collaborators.
MultiverSeg represents the next leap in biomedical imaging. It’s interesting to note that the model works like kids acquire learning. They stumble, make mistakes, and with each try they get a bit better. That is exactly what MIT’s MultiverSeg is doing. At first, it guesses about what’s in an image, initially it can be clumsy, but every time you correct it, it remembers and improves. Over time, you end up doing less and less work because it starts anticipating what you want.
The system transforms corrections into persistent knowledge, what researchers call “learnings”. Every time the system goes awry, a slight nudge is enough to position it in the right frame. While it’s at it, it starts picking up on your style and preferences. Isn’t it similar to how parents teach things to their toddlers?
As I was reading the research – MultiverSeg: Scalable Interactive Segmentation of Biomedical Imaging Datasets with In-Context Guidance – it actually reminds me of Klara and the Sun by Kazuo Ishiguro. Klara, the robot, doesn’t see the world the way we do at first, everything is fragmented, almost like looking through little boxes. But as she spends time with people, she starts piecing it together into something closer to human meaning. MultiverSeg is similar, your feedback turns raw, mechanical perception into something that feels aligned with human categories.
So, What’s MultiverSeg?
Before we directly go into the subject, let’s take this scenario. A medical researcher wants to study how a disease affects a tiny structure in the brain, say the hippocampus. To do that, he has to go through hundreds of MRI scans and carefully trace out the hippocampus in each one. That tracing is called “segmentation” by the way and it isn’t just boring, it’s painfully slow. Sometimes it’s so demanding that a researcher can only get through a handful of images in a whole day.
So, over the years, people have tried to fix this with two main approaches, but both come with headaches.
- Interactive tools: They are like those fancy paintbrushes, you draw a bit, click around, and the software tries to guess the rest of the outline. The process indeed is faster but the thing is, you have to go through that whole process again and again for every single image. It becomes this endless loop of scribble, guess, correct, repeat.
- Fully automatic models: They spit out segmentations with the automations but they only work if you’ve already fed them hundreds of perfectly annotated examples to learn from, which takes ages to prepare. Another pain point is, once the model is set, and while in process it makes a mistake, one can’t really step in and nudge it back on track.
Let’s compare how these approaches really differ when it comes to the work involved:
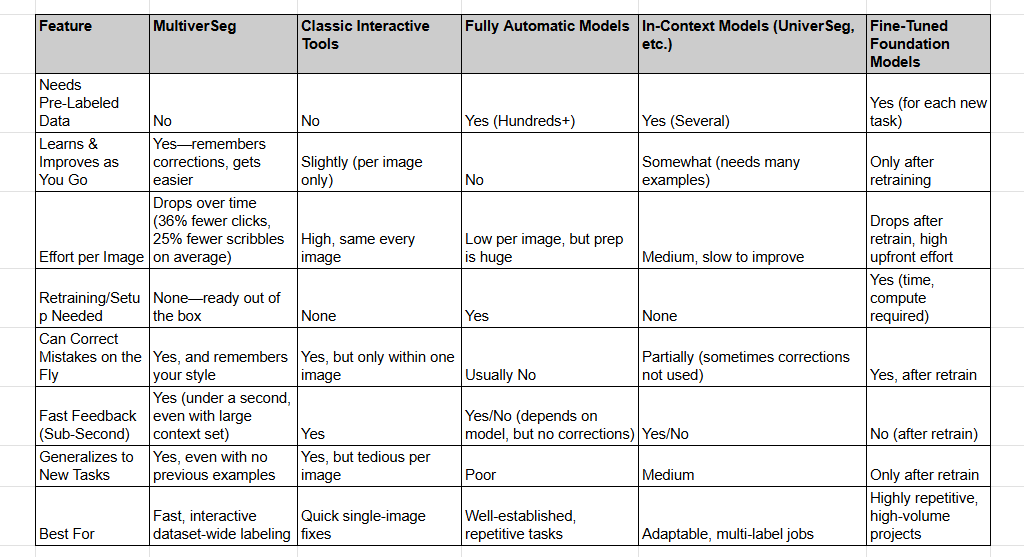
MultiverSeg helps in removing all these blockers. Firstly, it’s interactive, which means, it can only be guided but it also learns on the go. The more images a person works on, the more it picks up on the intended corrections, so over time it gets sharper and needs less supervision. Here is a step-by-step guide of the entire process.
MultiverSeg: The Segmentation Tool That Feels Like Ex Machina
Just think about from a user perspective, how draining and time consuming it can be to segment a large dataset, where repetitively one has to click and label image after image just to train a model. Now imagine an assistant that learns alongside the user, shaving down workload with every interaction, that’s what MultiverSeg does.
Instead of endless manual adjustments, MultiverSeg begins to meet users halfway. It dramatically reduces the effort required: 36% fewer clicks, 25% fewer scribble steps, and in some cases, segmenting just one or two X-rays is enough for the model to handle the rest. Tasks that once felt mechanical start to feel almost… conversational.
An equally interesting aspect is that you don’t need to be a machine learning expert to make it work. No retraining or huge labeled datasets are required. Anyone can jump right in and start using it on a new task, after all, the system adapts in real time. It learns from the inputs on the fly and improves instantly, without requiring any training process.
That makes MultiverSeg not just efficient but also interactive and correctable. If the results aren’t satisfactory, users can refine it right away. But instead of starting from a blank slate, you’re correcting a model that’s already trying to anticipate you, like working with a junior colleague who remembers what you showed them yesterday and doesn’t make the same mistake twice.

Doesn’t the process resemble the AI in Ex Machina? Ava, (the AI) doesn’t just copy words but learns from tone, pauses, even unspoken intentions? That’s what made her feel uncanny, she was bridging the gap between human expression and machine response. MultiverSeg isn’t anywhere near sentient, but in a structural way, it’s doing something like that, which is, moving beyond simple edits to actually anticipating and adapting, so working with it feels more like collaboration than correction.
The trajectory, then, is more than a technical story. It’s a shift in the relationship between humans and machines. From humans doing all the work, to machines making crude drafts, to a future where the machine becomes a collaborator that learns on the fly, until human input becomes less about correction and more about guiding vision itself.
How Does MultiverSeg Work? A Step-by-Step Guide
MultiverSeg is designed to make segmenting an entire dataset of similar images progressively faster and easier.
- Starting Fresh: A researcher begins with the first image in their new dataset. They use simple tools to give the AI hints, like clicking, drawing a box around the area, or scribbling inside it. Based on these hints, MultiverSeg predicts the complete outline (the segmentation). The user can correct the prediction with more clicks or scribbles until it’s accurate.
- Building a “Context Set”: Once the first image is segmented accurately, it’s saved into what the system calls a “context set”. This set acts as the AI’s memory, holding examples of what the user wants to segment.
- Learning on the Job: When the researcher moves to the second image, MultiverSeg doesn’t just look at the new scribbles, it also refers to the first image-and-segmentation pair in its context set. By seeing a completed example, it makes a much better initial guess. As a result, the user needs to provide fewer clicks or scribbles to get an accurate result.
- Getting Smarter and Faster: As the user segments more images, each completed one is added to the context set. With a growing library of examples to learn from, MultiverSeg gets progressively better. The number of interactions needed to get a good result drops dramatically.
- Achieving Full Automation: Eventually, the context set becomes so rich with examples that for many new images, the user might not need to provide any clicks or scribbles at all. MultiverSeg can accurately segment the new image on its own, based purely on what it has learned from the context set.

MultiverSeg helps in removing all these blockers. Firstly, it’s interactive, which means, it can only be guided but it also learns on the go. The more images a person works on, the more it picks up on the intended corrections, so over time it gets sharper and needs less supervision. Here is a step-by-step guide of the entire process.
When MultiverSeg Stumbles
No AI is perfect, and MultiverSeg occasionally hits its limits. Here are some honest failure modes to keep in mind. The MIT team was refreshingly honest about this in their paper, and I think that honesty is worth highlighting.
The “Not Enough Data” Problem
Scenario 1: You Only Have 3-5 Images
In your first image, MultiverSeg actually performs worse than just using ScribblePrompt. It needs about 10.2 clicks on the first image, while ScribblePrompt only needs 7.6.
Because MultiverSeg is designed to learn, and learning requires examples. With an empty context set, it’s like a student walking into an exam without studying. Although, it has general knowledge from training, but it doesn’t know your specific task yet.
The break-even point varies, but for most medical imaging tasks, you need at least 5 images before MultiverSeg starts saving you time. For some challenging datasets, it’s more like 8-10 images.
The bottom line: If your entire dataset is just a handful of images, its better to use ScribblePrompt or SAM. MultiverSeg is a tool for people who have 50, 100, 500 images to annotate. It’s a marathon runner, not a sprinter.
The “Everything Looks Different” Problem
Scenario 2: Your Images Are All Over The Place
The researchers tested MultiverSeg on a breast ultrasound dataset called BUID. This dataset has both benign and malignant tumors, and everything looked very different from each other.
Benign tumors tend to be round, well-defined, with darker borders. Malignant tumors are irregular, infiltrative, sometimes barely distinguishable from surrounding tissue. They’re like trying to teach someone “fruit” by showing them a banana, then an apple, then a durian, then a dragonfruit. Technically all fruit, but it’s not that straightforward to identify the pattern.
When the MIT team tested MultiverSeg on BUID with clicks, it underperformed ScribblePrompt until the context set had at least 5 examples. The AI was basically going, “Wait, I thought we were looking for round bright spots? Now you’re showing me irregular dark patches with fuzzy edges? Make up your mind!”
But here’s the interesting part, even with this challenging dataset, by image 8-10, MultiverSeg figured it out. It learned that “tumor in BUID” means “lots of visual variation, but here are the subtle commonalities.”
When scribbles were used instead of clicks (which provide more information per interaction), the performance gap basically disappeared. Scribbles gave the AI enough context to understand the variability faster.
The bottom line: If you know your dataset is highly heterogeneous, either:
- Be patient through the first 8-10 images
- Use scribbles instead of clicks for richer guidance
- Seed your context set strategically with diverse examples

The “Need It Right Now” Problem
Scenario 3: Real-Time Applications
ScribblePrompt runs in about 10 milliseconds. Blink and it’s done. You can barely perceive the delay.
- MultiverSeg with just 1 example in the context set? About 25 milliseconds. Still pretty fast.
- MultiverSeg with 16 examples? 57 milliseconds.
- MultiverSeg with 64 examples? 146 milliseconds.
For most research applications, 146ms is totally fine. You click, you wait less than a blink, you see the result. But if you’re doing something real-time, like surgical guidance where a surgeon is relying on immediate feedback, or live ultrasound where the probe is moving, that 146ms latency could be problematic.
There’s also a memory consideration. With 64 context examples, MultiverSeg uses about 7.1 GB of GPU memory. With 256 examples (if you really wanted to push it), you’re at 24.2 GB. That requires serious hardware.
The bottom line: MultiverSeg is optimized for throughput (process lots of images efficiently), not latency (process one image as fast as possible). It’s the difference between FedEx (gets your package there eventually, efficiently handling millions) and a courier (one person, one package, right now).
The “Imperfect Context” Problem
Scenario 4: The Oracle Gap
This one’s subtle but important. MultiverSeg was trained using perfect, ground-truth segmentations in the context set. Like, imagine you’re teaching someone to identify birds, and you show them perfect, professionally photographed, correctly labeled examples.
But in real life, when you use MultiverSeg, the context set contains the AI’s previous predictions, which aren’t perfect. Now you’re teaching someone with amateur photos where maybe the bird is slightly mislabeled.
The researchers found this creates a 5-8% performance gap compared to the “oracle” scenario where ground truth labels are used. It’s like training a student with perfect textbook examples, then throwing them into the messy real world. The student does okay, but not quite as well as you’d hoped.
So they fixed it with the threshold of the predictions at 0.5 before adding them to the context set. Basically, force the AI to commit, it’s either foreground or background, no wishy-washy probabilities. And this approach actually helped the model. It was trained on binary masks, so giving it binary masks at inference time (even if they’re imperfect) works better than soft probability maps.
The gap doesn’t disappear entirely, but it shrinks significantly. And interestingly, the more images you segment, the less this matters, because errors tend to average out as the context set grows.
The “3D Coherence” Problem
Scenario 5: Volumetric Medical Imaging
Here’s a limitation that’s more about what the system doesn’t do yet, MultiverSeg processes 2D slices independently.
In medical imaging, you often have 3D volumes, like a CT scan of the brain with 200 slices. MultiverSeg will happily segment each slice, and the context set helps maintain consistency, but it doesn’t enforce volumetric coherence.
Slice 47 doesn’t know what slice 46 or 48 decided. So you might get slight inconsistencies, like the boundary of the hippocampus jumping 2 pixels between consecutive slices, which anatomically doesn’t make sense.
The paper mentions this is a direction for future work. True 3D context with volumetric attention would be amazing but also computationally expensive. For now, the 2D approach is a practical compromise that works surprisingly well (the context set provides consistency across similar slices), but it’s not perfect.
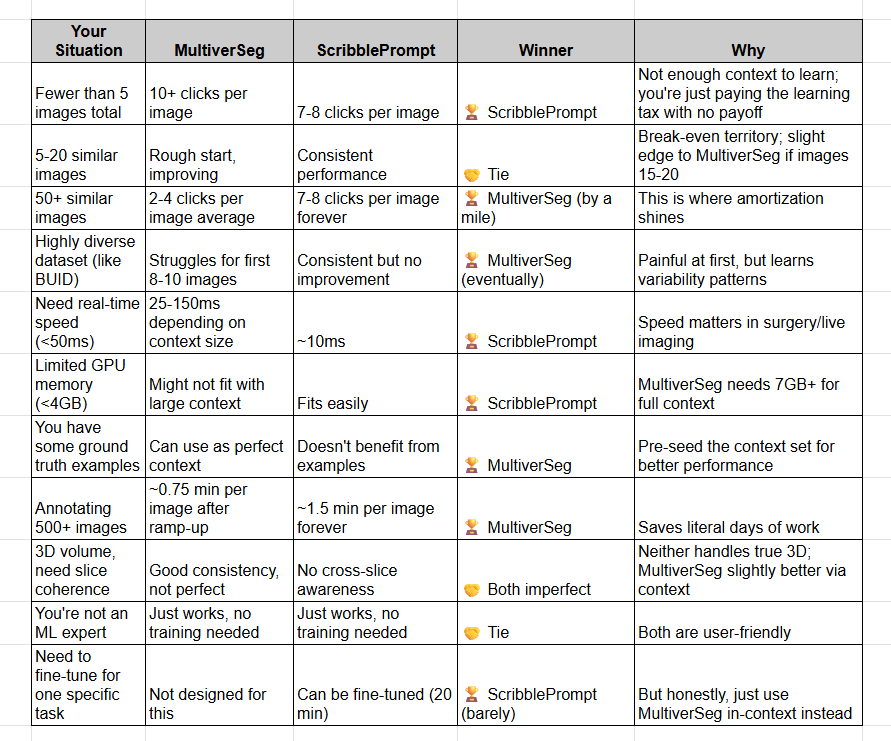
The Comparison: When to Use What
Okay, let me put this all together in a way that’s actually useful for decision-making:
What About Bootstrapping Other Models?
The MIT team tried something interesting, they used UniverSeg (a pure in-context model, no interaction) to bootstrap the process. It’s like segmenting the first image manually, then let UniverSeg auto-segment the rest using that as context. The result was not satisfactory, rather it failed.
There were two main reasons:
- UniverSeg has poor performance for small context sets (needs 16+ examples to be decent)
- When it makes a mistake, it adds that mistake to the context set, and then makes similar mistakes on the next image. Error compounds.
The takeaway: Pure automation works when you have a huge context set and the model is really good. But in practical scenarios where you’re building the context set as you go, you need the human-in-the-loop correction mechanism that MultiverSeg provides.
The Pattern Recognition Problem
MultiverSeg excels when there’s structure to learn. “Segment the hippocampus in brain MRIs” has structure, the hippocampus has a characteristic shape, size, location, intensity. After 10 examples, the AI has learned what “hippocampus” means in your specific imaging protocol.
But what if your task is, “Segment anything that looks interesting to me personally”? Or “Segment regions where I, as a domain expert, notice something unusual that I can’t quite articulate”?
That’s when MultiverSeg would struggle. It can learn patterns, but it can’t read your mind about what’s “interesting” unless that concept has consistent visual features. But then this pattern recognition problem happens with nearly all current AI models.
The bottom line: Most medical imaging tasks do have structure, for instance, organs have shapes, tumors have characteristics. In fact, cells have morphology. But if your task is highly subjective or based on implicit expert knowledge that doesn’t correlate with visual features, even the best AI will hit a wall.

My Honest Assessment
After digging through all this, here’s my take:
MultiverSeg is not a magic bullet. On your first image, it’s actually worse than simpler tools but for tiny datasets, it’s overkill. For real-time applications, it’s too slow.
But for its intended use case, segmenting dozens to hundreds of similar medical images, it’s genuinely transformative. The learning curve is real, but the payoff is substantial. You invest extra effort on images 1-5, and then you’re rewarded with progressively less work for the next 495 images.
The key is knowing when to use it, not every nail needs a sledgehammer. But when you have a lot of nails to drive, you want the best tool for sustained work.
And that’s what MultiverSeg is, the best tool for sustained, large-scale segmentation work where you can’t afford (or don’t want) to train task-specific models, but you also can’t spend weeks clicking through images manually.
It’s honest about its limitations. It doesn’t promise zero-click perfection from image one. It asks for patience and in return, it delivers something genuinely useful, a system that gets smarter the more you work with it.
We’ve spent decades building machines that perform tasks. Now we’re beginning to build machines that learn how we perform them. That shift , from automation to collaboration, is subtle but seismic.
If a machine can learn our ways, our intentions, our styles, then our role is no longer to command, but to guide.
The question is, are we ready to share the creative space with something that learns from us, and maybe, one day, starts to anticipate us?