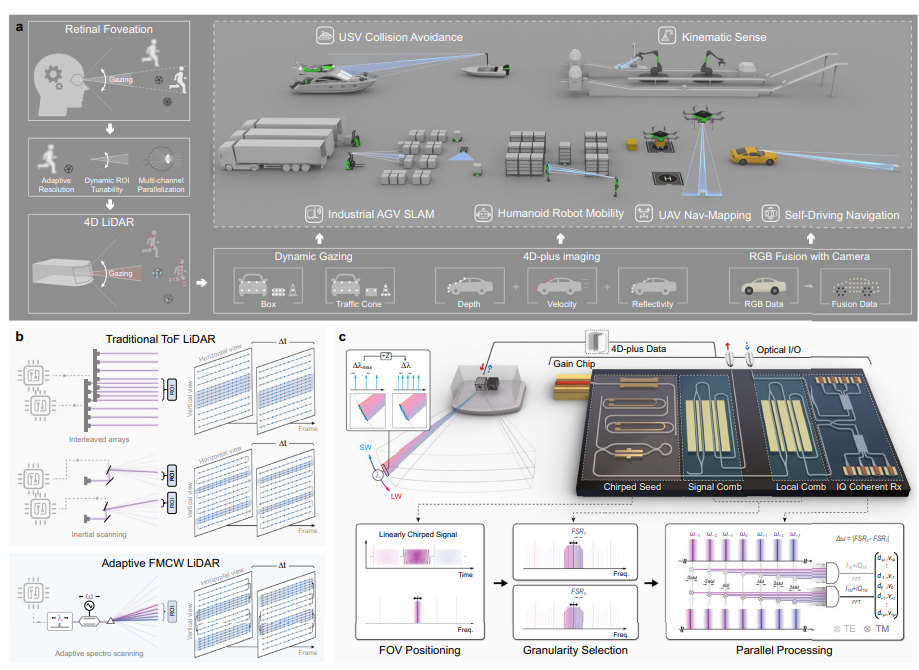
Have you ever noticed that our eyes don’t focus on every single brick in every building with the same intensity as when we are walking down the street? Instead, our brain “gazes”, narrowing its focus on, which it thinks is super important, like a child chasing a ball towards the road or a cyclist drifting too close. Everything else stays in view, but it fades into the background, without demanding any attention. This is our macula at work, delivering sharp detail exactly where our attention is needed most.
For years, machine vision has lacked this elegant efficiency. Standard LiDAR (the “laser eyes” of self-driving cars) is typically a “brute force” tool, scanning every inch of a scene with the same rigid resolution. This leads to a massive flood of data and high power consumption, along with hardware that is often too bulky and expensive for widespread use.
Now, a multi-institutional research team, including experts from Peking University and the City University of Hong Kong, has bridged this gap. In a study published in Nature Communications, researchers unveiled a retina-inspired, chip-scale LiDAR that can actually “gaze” at specific objects, seeing them with a resolution that actually surpasses the human eye.
Higher Resolution Usually Meant More Hardware
Traditional LiDAR systems had a bottleneck, to get better resolution, it usually needed more hardware. It’s like trying to make a digital photo clearer by simply adding more and more cameras, which eventually led to a complex and power-hungry visual system.
The new approach is different, the bionic system uses a “micro-parallelism” strategy.
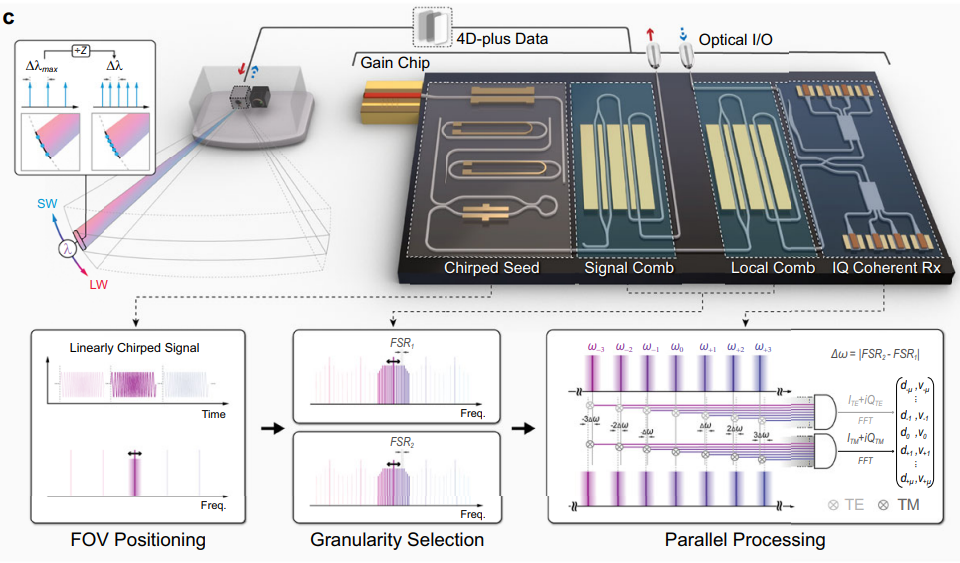
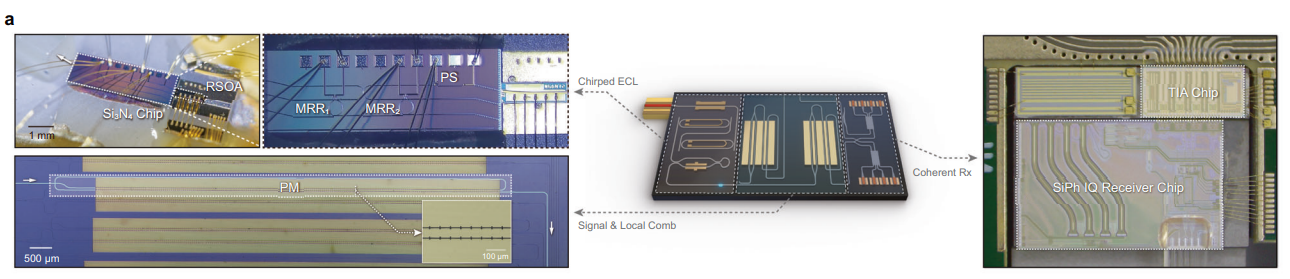
By using a chip-scale platform made of thin-film lithium niobate (TFLN), the researchers created a system that doesn’t just scan, it adapts.
It can allocate its sensing resources to “critical regions” without wasting energy on irrelevant background data.
The Optical Idea That Makes Gazing Possible
The trick lies in what’s called an electro-optic frequency comb. It’s like saying one laser beam splitting into multiple evenly spaced channels. Once that’s in place, the system can do a few things that traditional LiDAR struggles with.
1) Dynamic Gazing: By adjusting the repetition rate of this comb, the system can change the granularity of its vision. It can look at a wide FOV (field of view) and then instantly zoom in on an object of interest, like a road sign or a pedestrian.
2) 4D-Plus Vision: This isn’t just a 3D map. The system provides 4D imaging, capturing distance and velocity simultaneously. When paired with a standard camera, it creates “4D-plus” vision, fusing depth and speed with real-world color.
3) Real-Time Speed: Because the hardware is so efficient, it can process data in real-time, handling up to 1.7 million pixels per second.
Seeing The Difference In Real Scenes
What’s interesting is how quickly the theory turns into something we can see on a screen.
On paper, the resolution numbers already stand out. The human eye generally needs about 0.017 degrees to distinguish fine detail. In its focused regions, this LiDAR system reaches around 0.012 degrees.
That gap might sound small, but in sensing terms it’s the difference between noticing an object and understanding what it is. Most conventional 3D LiDAR systems sit far below that level unless they rely on bulky hardware or heavy data processing.
In practice, the contrast is obvious. During a simulated road test, a uniform scan treated everything equally and paid the price for it. Small traffic cones faded into the scene. Text on a “speed limit 80” sign blurred into something unreadable.
When the gaze function redirected its attention, those same objects snapped into clarity. The system didn’t just detect them, it resolved their shape and structure.
The basketball test is a good example of why this matters. Instead of seeing the ball as a single moving point, the LiDAR captured how different parts of its surface were moving at slightly different speeds.
That kind of detail opens the door to understanding motion, not just measuring it. For robots and autonomous systems, that distinction is the difference between reacting to the world and actually interpreting what’s happening in front of them.
Takeaway
Where this really starts to matter is when you think about what autonomy actually needs.
Most autonomous systems today aren’t limited by algorithms as much as they’re limited by sensors. High power draw and constant data overload make it hard to deploy vision systems beyond controlled environments. By pushing this LiDAR down to a chip-scale design, those constraints loosen.
It becomes light enough to sit on a drone without cutting flight time in half. Small and responsive enough to fit on a humanoid robot without slowing its movements. Efficient enough to run continuously in a car without turning into a thermal problem.
The more interesting shift, though, is cognitive. Instead of treating the world as a flat wall of measurements, this approach lets machines decide what deserves attention.
A pedestrian stepping off the curb matters more than a static building. A sudden change in motion matters more than background texture. That’s how animals with limited neural resources survive, and it’s how human drivers manage complex roads without thinking about every object they pass.
Because the system can be fabricated at scale and doesn’t rely on oversized optics, it fits into real products, not just lab setups. It points toward autonomous machines that don’t just collect more data, but make better sense of it by focusing on the right moments at the right time.
Frequently Asked Questions
1. What is retina-inspired LiDAR?
Retina-inspired LiDAR is a sensing approach that mimics how human vision works. Instead of scanning every part of a scene with equal detail, it focuses higher resolution on areas that matter most, while keeping the rest of the scene in lower detail. This reduces data load and improves efficiency.
2. How is this different from traditional LiDAR systems?
Traditional LiDAR scans everything uniformly, which often means more hardware, higher power use, and large amounts of data. This system adapts its focus, allocating resources to important regions rather than treating the entire scene the same way.
3. What is an electro-optic frequency comb in simple terms?
It’s a way of splitting a single laser into many evenly spaced light channels. These channels work together, allowing the LiDAR to scan faster, adjust resolution on the fly, and capture more information without adding extra lasers or sensors.
4. What does 4D imaging mean in LiDAR?
4D imaging means the system captures not only three-dimensional position but also velocity. It measures how fast objects are moving and in which direction, which is essential for understanding dynamic scenes like traffic or crowds.
5. Why is higher angular resolution important?
Higher resolution allows the system to move beyond basic detection and into recognition. It’s the difference between spotting an object and understanding what it is, such as reading a traffic sign or distinguishing a small obstacle on the road.
6. Where could this type of LiDAR be used?
Because it’s built on a chip-scale platform, this LiDAR is suitable for drones, mobile robots, humanoid systems, and autonomous vehicles. Its low power use and compact size make it practical outside of laboratory environments.
7. How does adaptive “gazing” improve safety in autonomous systems?
Adaptive gazing lets a system prioritize sudden changes or moving objects, like pedestrians or vehicles braking unexpectedly. By focusing attention where it’s needed most, the system can respond faster and more accurately to real-world situations.
Source: Ruixuan Chen et al, Integrated bionic LiDAR for adaptive 4D machine vision, Nature Communications (2025). DOI: 10.1038/s41467-025-66529-7