
Researchers at Technical University of Denmark have found an interesting connection between how humans learn and how computers learn. It talks about a special shape in math called convexity. This shape might help us understand how our brains and computer programs figure out ideas and understand things around us.
I was able to dig deep via a paper titled, “On convex decision regions in deep network representations,” published in Nature Communications. It talks about how concepts show up in neural network latent spaces, specifically whether they form convex regions. The idea ties back to Peter Gärdenfors’ theory of conceptual spaces in cognitive science, where human concepts are often modeled as convex regions in a geometric space. In simple words, conceptual spaces in cognitive science is a theory developed by Peter Gärdenfors, according to which, we understand concepts, not with symbols or logic, but geometrically.
Gärdenfors’ Conceptual Spaces
Conceptual spaces are a way of explaining how our brains understand ideas. Instead of thinking about concepts as just symbols or words, this idea says we imagine them as shapes or areas in a kind of mental space. Each concept has specific features, like color, size, or position, which can be measured and related to each other visually. This helps us see how different ideas are connected and how we perceive their meaning based on our senses, rather than just using words or abstract symbols.
More or less, it’s like a map where each concept is a neighborhood defined by features like color, size, or position. Just like how you can see which neighborhoods are close or far apart on a map, this helps us understand how different ideas are connected and how we perceive their meaning based on our senses, not just words or symbols.
Do Machines Think Like Us?
The broader goal of the paper is to understand how machines organize knowledge and whether that structure lines up with how humans think. That alignment is critical in areas like healthcare, education, and policy, where machines assist people in making decisions. One way to bridge the gap is to look at how concepts are represented internally by models.
Translating that to neural networks
Lenka Tetkova, is a postdoc at DTU Compute, and her team tried to explore how deep neural networks understand and group ideas like “dog” inside their internal way of organizing information. She asked whether these internal regions, where the network “thinks” about a concept, are shaped in a way called convex. For this, they explore two kinds of convexity:
1. Euclidean Convexity: It’s like drawing a straight line between two points that represent two different “dogs” in the network’s internal space. If the space for “dog” is convex, then every point along that straight line will also be seen by the network as a “dog”. So, blending two dogs quickly and simply would still result in something familiar to the network.
For example, if you pick any two dog pictures and imagine mixing them directly, like drawing a straight line between them, all the pictures in the middle should still look like dogs, that’s what Euclidean convexity looks like.
2. Geodesic or Graph Convexity: Sometimes, the space inside the network isn’t flat but curved, kind of like the surface of a hill or a sphere. Instead of drawing a straight line, you find the shortest path along the curve or surface that connects two points (called a geodesic). If the space is convex in this curved sense, then this shortest “curved” path connecting two “dog” points stays within the “dog” region. They use graph-based methods to estimate these shortest paths on the curved space.
Geodesic convexity means instead of mixing them (two dog pictures) in a straight line, you follow a path that goes around, like walking through a maze that connects those two dog pictures. If every step along that path still looks like a dog, then the group has geodesic convexity.
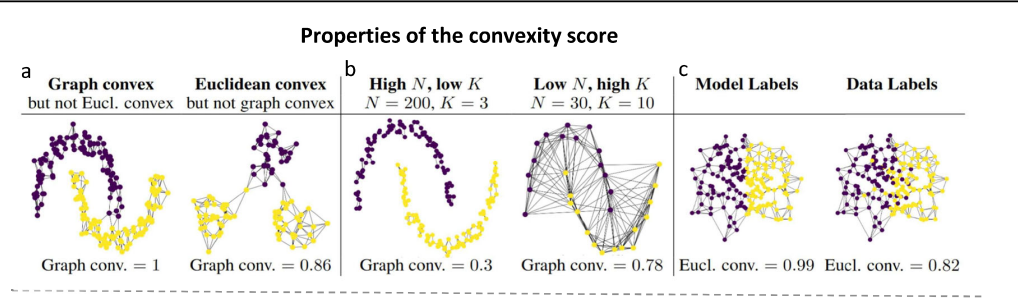
Convexity Shows up in Models
Convexity shows up in machine learning models because many parts of these models naturally create or resemble convex shapes or boundaries.
- For example, softmax layers, which are used to decide classes or categories, act like simple straight-line classifiers that divide data into groups with smooth, bowl-shaped boundaries, these are convex shapes.
- Similarly, attention mechanisms also use softmax functions, so the same idea applies that they tend to produce smooth, convex decision regions.
- ReLU (rectified linear unit) functions, which are common activation functions, work by splitting space into half-planes, it’s like dividing space with a straight line. These half-spaces are by definition convex shapes. Although neural networks built with ReLUs can produce very complicated and jagged borders, they often end up behaving in a way that is smoother and more convex than expected.
So, even if the models aren’t designed to be convex on purpose, many parts of them naturally have convex properties.
Different Class Regions were Shaped in the Space
The team built two methods for checking how “convex” or “bulged out” the areas where a model predicts certain classes are. Here’s a simple breakdown:
1. Graph Convexity:
- They make a network of points called a “graph” where each point is connected to nearby points (nearest neighbors).
- For any two points assigned to the same class, they find the shortest route between them in this graph, like finding the quickest path in a map.
- They check if all the points along this shortest route are also classified as that same class.
- They do this many times for different points and average the results to see if the class regions are generally convex.
2. Euclidean Convexity:
- They pick two points of the same class and draw a straight line between them in a special space called the “latent space” (a kind of feature space the model uses).
- They create new points along this line by mixing the original points (interpolating).
- These new points are then passed through the model to see what class it predicts for them.
- They check how many of these intermediate points stay in the same class, then average the results across multiple pairs and layers.
Overall, they use the model’s predictions to understand how the different class regions are shaped in the space the model uses to make decisions.
Tested on Five Types of Data
They ran this across five types of data:
- Images: using ViT, DINOv2, BEiT, and others
- Audio: models like wav2vec2 and HuBERT
- Text: BERT, RoBERTa, LUKE, etc.
- Human Activity: 1D CNNs trained on data from wearable sensors
- Medical Imaging: ViT models on blood cell classification
Some models were only pretrained, others were also fine-tuned for specific tasks.
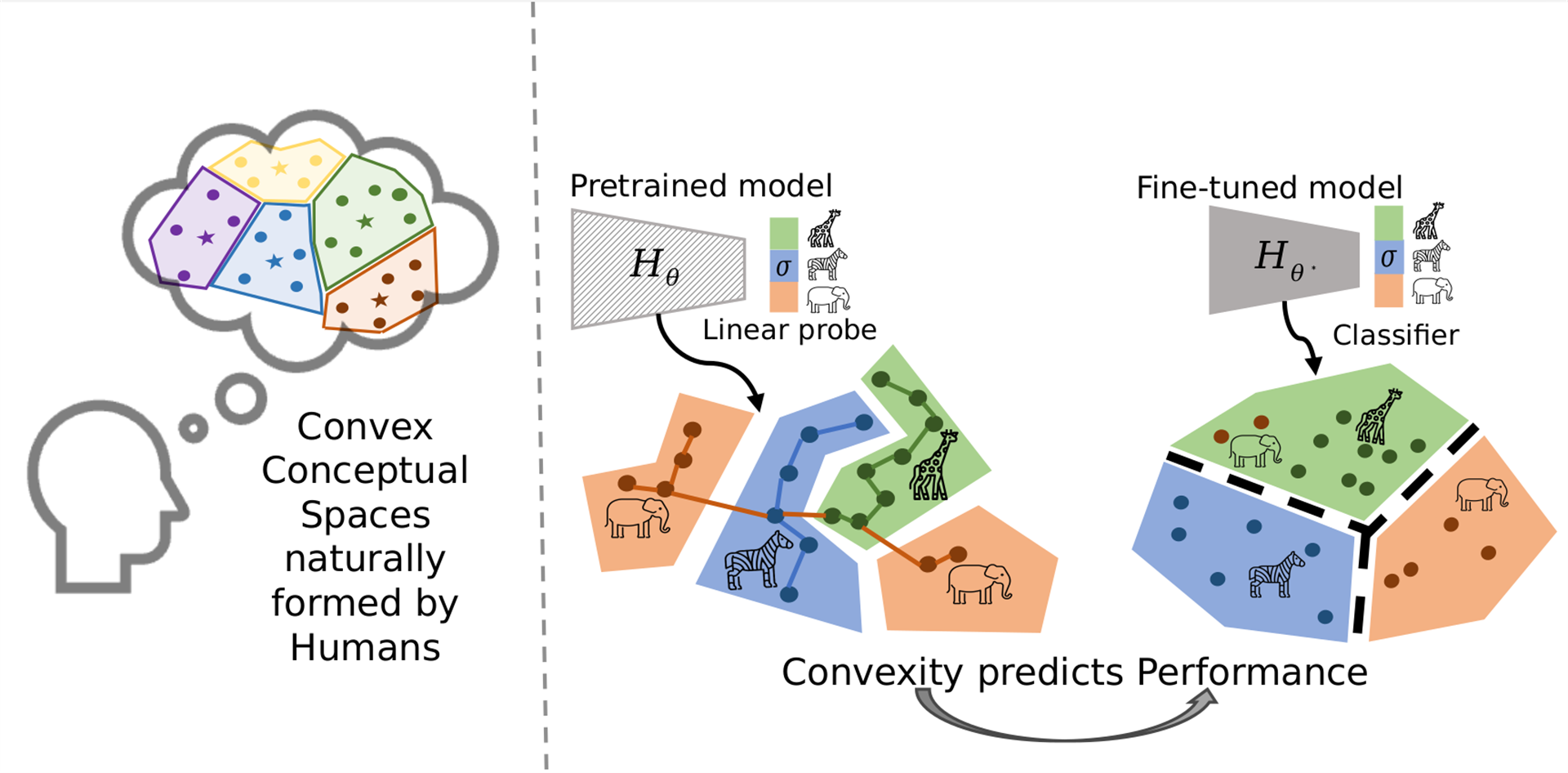
Highlights of the Test
A few takeaways stood out:
- Commonality: Across all domains, both types of convexity showed up consistently, even in the early layers of pretrained models.
- Growth: Convexity grows with depth and fine-tuning. The deeper into the model you go, the more convex the concept regions get. Fine-tuning also boosts convexity.
- Prediction: Better convexity predicts better performance. They found a strong correlation between how convex a class’s region was in the pretrained model and how well that class did after fine-tuning. Correlation coefficients were around 0.52 to 0.53, which is solid.
- Comparison: Convexity is more informative than intrinsic dimensionality when it comes to predicting downstream performance.
In short, convexity is a reliable and consistent feature in how models represent concepts. When a concept is convex, it means the model can group all related examples together smoothly, and this property becomes stronger as the model learns more. Also, if a concept has high convexity before adjusting the model, it usually means the model will do a good job with that concept after further training. Because of these qualities, convexity helps us see how well a model is learning and where it might perform best or need improvement.
Convexity Helps Pick and Improve Models Early
This gives us a way to evaluate or even select models before fine-tuning. If a class has a high convexity score in a pretrained model, it’s likely to generalize better with fewer examples. That’s helpful if you’re working with limited labeled data.
It also helps make the model’s internal structure a little more interpretable. If concepts are neatly organized into convex regions, they’re easier to reason about, debug, and align with human labels.
They’ve even used convexity scores to prune models more intelligently before fine-tuning—leading to better performance with less computation.
Takeaway
There’s a lot of potential here, Convexity offers a practical, measurable link between how models learn and how humans think. It also gives us a useful tool for aligning machine learning systems with human reasoning, especially in high-stakes fields. One challenge is that measuring convexity can be computationally expensive at scale, so there’s room to make it more efficient.
But overall, this work helps connect theory and practice in a way that’s clear and useful.
Source: Technical University of Denmark


[…] Measuring Convexity in AI: Linking Machine Learning to Human Concept Understanding […]