You’d expect the same input to get the same answer, right? But in machine learning, that’s not always the case.
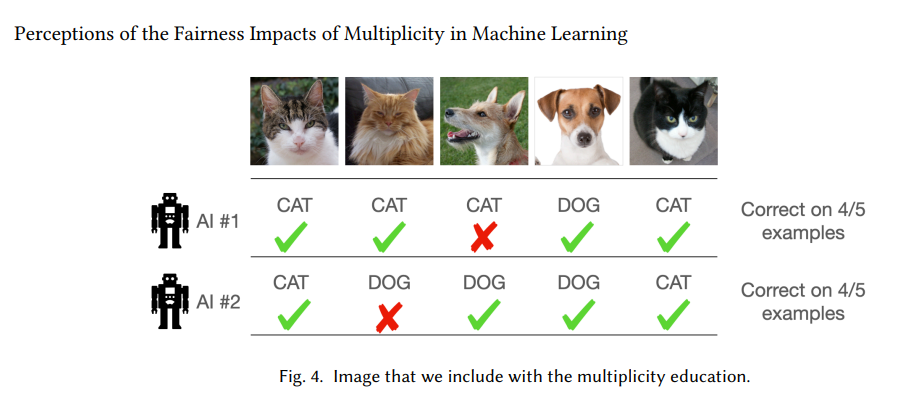
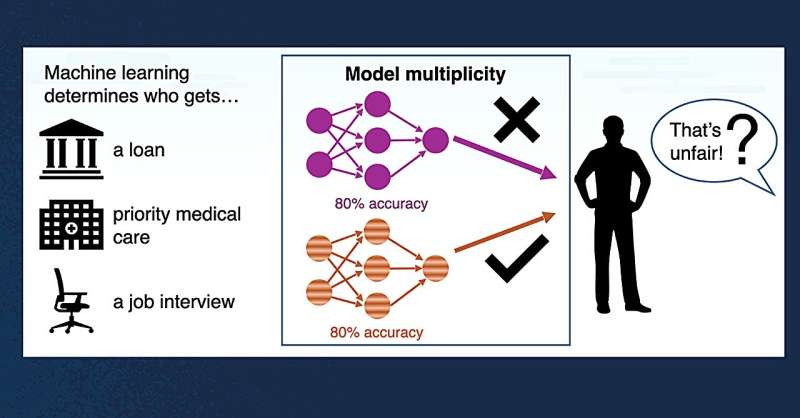
The paper “Perceptions of the Fairness Impacts of Multiplicity in Machine Learning” looks at a problem in machine learning that most people outside the field probably haven’t heard of, but should, it’s called the multiplicity. That’s when you have several ML models that are all equally accurate overall, but give different answers for the same person. So if you’re applying for a credit card, one model might say “yes”, while another one, just as accurate, might say “no”.
The research was led by Associate Professor Loris D’Antoni, now at UC San Diego in the Jacobs School of Engineering. He started the work while at the University of Wisconsin and recently presented it at CHI 2025 (a major conference focused on how humans interact with technology). The full paper is available on the arXiv preprint server, if you want to dive into the technical details.
What is Multiplicity?
Multiplicity means that one situation or problem can have many different explanations or solutions. In this analogy, going to five good doctors for the same symptoms and getting five different diagnoses shows that even when experts follow proper methods, they can see the same thing in different ways. One doctor might think it’s stress, another might think it’s a virus, and another might prescribe antibiotics. This shows that the same symptoms can be caused by different things, and different experts might interpret the same information differently.
That’s what happens with multiplicity in ML. Different models trained on the same data can make different calls, even when they’re all considered “high-performing”. In fact, in one commonly used dataset for predicting criminal reoffending (COMPAS), up to 69% of test inputs had different predictions depending on which model was used.
This means that when computers make decisions based on data, people assume algorithmic decisions are purely data-driven. But in reality, what model is used can also change the result. So, even if two people have the same data, they might get different outcomes because of which program or model was chosen. This can seem unfair, especially when the decision affects important things like jobs, loans, or healthcare.
What Did the Study Actually Look At?
D’Antoni and his team wanted to understand how everyday people (not just experts) feel about this issue. They surveyed 358 U.S.-based participants, many recruited from online platforms, and asked three main questions:
- Does telling people about multiplicity make them think the system is less fair?
- What kinds of solutions do people prefer to deal with it?
- Do people’s answers change based on how serious or high-stakes the situation is?
Breaking It Down
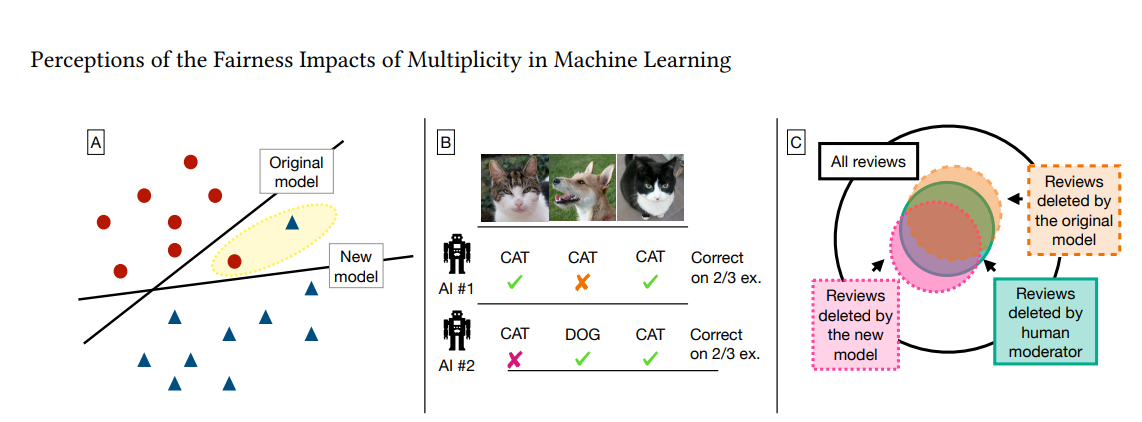
Participants went through a short tutorial explaining what multiplicity is. Then they were given a scenario, like applying for a job, being put on medical probation, or getting access to a treatment plan.
First, they rated how fair they thought the system was before knowing about multiplicity. Then they were told that equally accurate models could have made different decisions, and asked again.
They were also shown different ways to resolve multiplicity and had to choose which ones felt fairest. Here’s a quick rundown of the options:
- Default to the bad outcome (e.g., deny the job or benefit)
- Default to the good outcome (e.g., approve it)
- Use a fancier model that tries to smooth out the differences
- Let a human expert decide
- Ignore it entirely
- Pick randomly
What People Said
1. Fairness judgments didn’t collapse
Surprisingly, people didn’t lose much trust in the system after learning about multiplicity. Their views on whether the outcomes were fair dropped a little, but most still felt the use of the model itself was appropriate. So learning that models disagreed didn’t make people throw out the whole system, it just made them more cautious about its decisions.
2. People want a human involved
The best way to handle many options or choices is to have a person who is knowledgeable make the decision. In most comparisons, about 80%, people chose this human expert as the better choice. This was true in different types of tasks and situations.
That makes sense if you think about it. When something serious is on the line, like your job or health, you probably want a human in the loop, not just a machine.
3. No random outcomes
Most people don’t like the idea of making a decision by just picking randomly. Even though some say randomness might be fair when there’s no clear best answer, most participants dislike it. They think it feels unfair and unfairness is worse when they expect a fair and objective process, like an algorithm, to make the decision.
It’s like saying applying for a scholarship and the final decision came down to flipping a coin. Even if the coin is “fair”, you’d probably feel cheated. That’s how many people saw randomization in algorithmic decisions.
4. Context matters
People’s preferences shifted based on the kind of task:
- High-stakes situations (like medical treatment): More support for human intervention
- Low-stakes settings: People were a bit more open to things like default-bad or random, though neither was ever super popular
- Reward scenarios (getting a job): People leaned toward defaulting to the good outcome
- Punishment scenarios (being put on probation): Default-bad was more accepted
Interestingly, whether the task was more uncertain didn’t really change people’s views. But extra cost did, people preferred cheaper solutions unless the task was really important. For things like cancer screening or job probation, they were more okay with added cost if it meant a better resolution method.
How People Actually Want Machine Learning to Work
This research pushes back against how machine learning is typically done. In most workflows, developers train a bunch of models, pick the one that performs best overall, and use it. Multiplicity gets ignored but that doesn’t match how people want decisions to be made, especially when those decisions affect their lives. A few pointers:
- People expect transparency. Just knowing multiplicity exists didn’t destroy trust, but people want to know it’s being handled thoughtfully.
- Human involvement still matters. Algorithms are seen as tools, not final judges.
- Random might be “fair” in theory, but it doesn’t feel that way in practice.
- Context is key. Developers shouldn’t assume one solution fits all, they should tailor it to the task and involve users in those decisions.
Some Limitations
The researchers pointed out some things that might affect the results:
- Multiplicity is a tough concept. Even with explanations, some participants may not have fully understood it.
- Scenarios were simplified. In real life, knowing your personal outcome or seeing model explanations might change how you feel.
- The sample was U.S.-based, so cultural differences weren’t captured.
- The study showed what people prefer, but not why they feel that way. That’s a big area for future research, especially around the strong dislike of randomization.
Takeaway
In short, this study shows that regular people do care about fairness in algorithmic decisions, even if they don’t speak the same language as developers or ethicists. Multiplicity might seem like a technical quirk, but underneath it is something deeply human, a desire for consistency, for explanations that make sense, and for decisions that feel just.
It’s a reminder that even the smartest systems are still part of a larger social world. When algorithms shape outcomes that matter, jobs, healthcare, freedom, people want to know that those decisions aren’t arbitrary. They want to feel seen in the process, not just processed by it.
As research like this continues at UC San Diego under Professor D’Antoni’s guidance, it challenges the field to slow down and listen, not just to data, but to the people on the receiving end. Because fairness in machine learning isn’t just about performance metrics. It’s about trust. And trust is earned, not assumed.
Source: Techxplore