
Researchers at the Technical University of Denmark have found a fascinating link between how humans and machines learn, through a mathematical shape called convexity. This concept could be key to understanding how both brains and algorithms organize ideas and make sense of the world. I stumbled upon their paper, “On Convex Decision Regions in Deep Network Representations,” and I was absolutely awestruck. Not just by the insights in the research itself, but by the sheer brilliance behind it. It’s one thing to read a paper that makes you think differently, it’s another to get the chance to speak to the mind that imagined and built it.
For me, reading research papers and connecting with the people behind them is a joy unlike any other. When I get lucky enough to land an interview, everything else takes a backseat. I dive headfirst into crafting questions, piecing together the story behind the science, and soaking in every answer like a curious student. Nothing makes me feel more alive than talking to the intellectuals shaping the future of knowledge.
And today, I’m thrilled, truly thrilled, to share my conversation with Dr. Lenka Tetkova, a postdoctoral researcher at DTU Compute. Her work doesn’t just push the boundaries of machine learning, it invites us to rethink what we expect from AI in the first place. From exploring how cognitive science can inspire more interpretable models to showing that deep networks might already be organizing knowledge in ways we can understand, Dr. Tetkova is helping transform AI from a black box into something much more human.
Let’s dive into one of the most fascinating intersections of geometry, cognition, and machine learning, and meet the brilliant mind behind it.
Can you tell us a little about your journey, what inspired you to get into AI and explainability research, and what has kept you passionate about this field?
My journey into AI began from a foundation in pure mathematics. While I loved the elegance and rigor of math, I often felt it lacked a tangible connection to the real world. That changed when I discovered machine learning—suddenly, abstract ideas could be applied to complex, messy problems in a way that felt deeply meaningful. But as I dug deeper into deep learning, I noticed a persistent gap: models were becoming impressively accurate, yet increasingly difficult to understand. We were optimizing performance, but losing interpretability.
At the same time, I’ve always been fascinated by how humans make sense of the world—how we perceive patterns, form concepts, and reason about what we see and hear. That curiosity naturally pulled me toward explainability research, where questions about human cognition and machine learning intersect.
What keeps me passionate is the belief that AI doesn’t have to be a black box. There’s something incredibly motivating about working toward systems that are not only powerful, but also transparent—systems whose decisions we can understand, trust, and even learn from. To me, explainability isn’t just a technical challenge—it’s a human one.
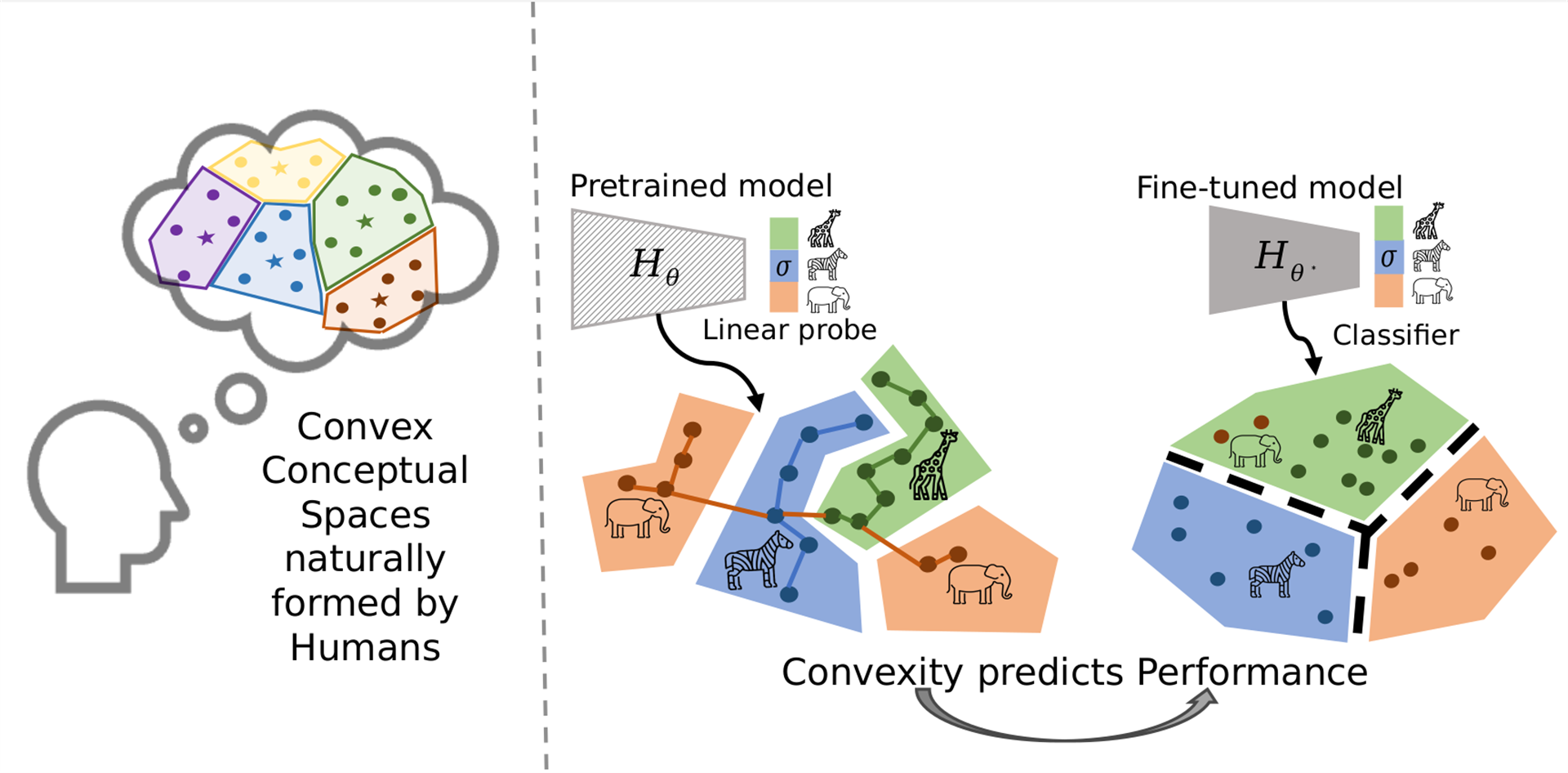
Your work is deeply inspired by Gärdenfors’ conceptual spaces, which propose that natural concepts form convex regions. Could you elaborate on how this idea from cognitive science initially sparked your investigation into convexity in machine-learned latent spaces, and how this cognitive perspective offers a novel lens compared to more traditional machine learning interpretability approaches?
Gärdenfors’ notion that concepts form convex regions in geometric space resonated with me as a compelling way to model how humans group and reason about similar experiences. When we began studying deep network representations, we saw striking parallels and wondered: do machine-learned concepts follow similar geometric principles? Exploring convexity in latent spaces became a way to connect cognitive theory with machine learning.
Unlike traditional interpretability methods that explain decisions after they are made, the conceptual spaces framework offers a geometric perspective — a way to evaluate whether a model’s internal structure aligns with human-like reasoning. That shift in perspective opens up new paths toward more intuitive, inherently interpretable AI.
During this extensive research on “On convex decision regions in deep network representations,” published in Nature Communications, what was the most surprising or unexpected discovery that challenged your initial assumptions about deep network representations?
The most surprising discovery was just how much convex the latent representations are even in earlier layers. We found that under certain training conditions, models naturally develop representations that are remarkably well-aligned with convex structures, even without explicit constraints and without showing them any labels. It suggested that interpretability might not always have to be imposed; sometimes it’s already latent in the model’s own learning process—we just need the right lens to see it.
Your research on “How Redundant Is the Transformer Stack in Speech Representation Models?” shows that up to 40% of transformer layers can be pruned without significant performance loss. How do you ensure that pruning these layers doesn’t degrade accuracy in voice AI tasks like emotion detection or speaker identification?
We approached pruning not as a brute-force compression task, but as a careful analysis of functional redundancy. Using layer similarity scores, we identified blocks of layers with highly similar latent representations. Surprisingly, many models had layers that acted more as pass-throughs than transformers. We found that most of these layers can be removed, as long as something from each block is kept. Then we tested whether downstream performance degraded when selectively removing less informative layers. By validating across multiple models trained for word classification, we ensured that pruning didn’t just preserve overall performance but also retained the right information.
This finding that big portions of the networks are redundant was also confirmed in our paper “Convexity Based Pruning of Speech Representation Models”, where the convexity score was used to detect the best layer for pruning. We found that it might even increase the performance in some cases.
One of your papers discusses using “symbolic hints” in image classification. How do these hints help the AI learn better or faster, especially when resources like data or computing power are limited?
The motivation for this work again started with observing how we, humans, learn and decide about the world around us. AI models these days are usually given a specific input (for example, an image or a short text) and need to make predictions only based on this single piece of information. In contrast to that, humans perceive much more information at once, even if we are not directly aware of it. But all this context influences how we look at the world and make decisions. The “symbolic hints” try to mimic this complexity and provide models with more information that could help them achieve better performance. In the paper, we propose a framework for integrating these hints without increasing the computational demands.
What do you see as the biggest challenges ahead for making AI more explainable and trustworthy?
The biggest challenge is balancing performance with inherent interpretability. Many of today’s models are trained to maximize accuracy without regard to how they arrive at their decisions. That often leads to brittle, uninterpretable systems. To truly trust AI, we need models that are not only accurate but also aligned with human-understandable concepts. Another major challenge is the gap between academic interpretability research and real-world deployment. It’s one thing to explain a model in a paper; it’s another to make that explanation actionable for a clinician or policymaker. Bridging that gap is where I see the field heading.
What’s one surprising or memorable moment from your research career so far that really shaped how you think about AI and its role in society?
I was struck by how differently children and AI learn. Kids use curiosity, analogy, and interaction; AI just optimizes a loss function on static data. That contrast reshaped my perspective and made me focus less on scale and more on how to design systems that learn in more human-like, structured, and explainable ways.
For aspiring scientists and students interested in the intersection of cognitive science, machine learning, and interpretability, what advice would you offer based on your experience with this groundbreaking work?
This field rewards persistence. Interpretability can feel messy and hard to measure, but that doesn’t make it less valuable—it makes it essential. Trust that clear, meaningful insights will outlast fleeting metrics. Also, remember that interpretability isn’t just about explaining models to other researchers—it’s about making AI systems more understandable, usable, and trustworthy for real people. Always ask: Who needs this explanation, and why?

Quick Bits
Can AI really understand humans, or is it just pretending?
Today, it’s mostly pretending. But the line between simulation and understanding may blur as models become more contextually grounded. The real question is: do we understand what kind of understanding we want?
If you could teach AI one human emotion, what would it be?
Empathy—not in a sentimental sense, but as the ability to model and respect others’ perspectives. It’s foundational to ethical alignment.
If you weren’t a scientist, what other career do you think you’d be doing right now?
I’m not entirely sure, I think many careers could make me happy. It would need to be intellectually challenging, but also have a positive impact on individual people or society as a whole.
What’s your go-to way to unwind after a long day in the lab or at the computer?
A long walk or run, ideally somewhere quiet and green, helps me reset. I also turn to something creative—dancing, knitting, or making music—as a way to shift gears and recharge in a different mode.
Wow! Thank you, Dr. Tetková, for an incredibly inspiring conversation! Your work is a true source of inspiration. We eagerly anticipate our next visit to witness more of your innovative research. Until then, we extend our best wishes for your continued success in all your future endeavors.


